raft算法
Contents
Raft 算法小结
raft 算法的主要模块:
- 选举
- 关系更新
- 日志复制
- 日志压缩
选举
raft为了避免操作混乱,使用了Quorom , 一种强领导的方式,所有的写操作到由leader处理,在由leader分发到follwer.这样所有的操作都会变成有序化,再将这些操作
应用到状态机即可。
Dynamo除了强一致性外,还支持最终一致性,由于是多写,Dynamo使用了向量时钟来纠正操作的时序。
raft的角色一共3种,Leader,Follower以及Candidate, 其中Leader是由选举产生的, Follower在集群没有Leader的情况下会进行投票选举,此时发起投票的节点就
变成了Candidate,如果选举成功,会变成Leader. 选举时,每个节点每次只能投出一票,如果同一时间有多个节点发起投票,那么其他节点也只会投一个节点的票。
关系的变更
关系的变换主要包括2中:Leader以及集群升级。
如果
Leader发生故障,检测到这个状态的Follower就会发起Leader选举,选出新的Leader。当升级集群时,
Raft会根据新旧配置进行升级。
日志复制
日志由Leader产生,然后分发到Follower。
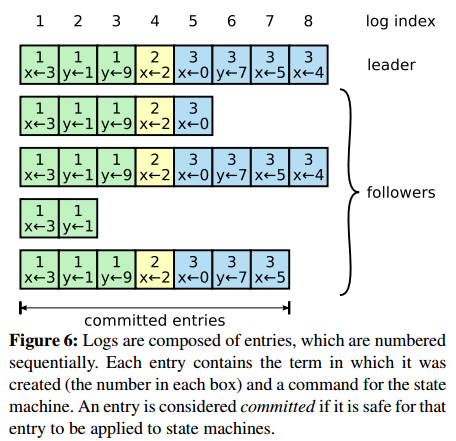
日志也是采用大多数应答的原则,如图(日志格式由任选期-index唯一标识)。
根据大多数原则,leader发起的日志复制已经committed的最新索引为任期3-index7,这些日志都已经被大多数(>=3)接收了,Leader就会将这条日志应用到状态机,然后commit了,并将结果返回给客户端。
每个log entry都存储着一条用于状态机的指令,同时保存从leader收到该entry时的term号。该term号可以用来判断一些log之间的不一致状态。每一个entry还有一个index指明自己在log中的位置。
leader需要决定什么时候将日志应用给状态机是安全的,被应用的entry叫committed。Raft保证committed entries持久化,并且最终被其他状态机应用。一个log entry一旦复制给了大多数节点就成为committed。同时要注意一种情况(如上图,假设leader发生故障,而第4个节点成为了新的Leader,此时这个节点的日志已经落后了好多),如果当前待提交entry之前有未提交的entry,即使是以前过时的leader创建的,只要满足已存储在大多数节点上就一次性按顺序都提交。leader要追踪最新的committed的index,并在每次AppendEntries RPCs(包括心跳)都要捎带,以使其他server知道一个log entry是已提交的,从而在它们本地的状态机上也应用。
Raft的日志机制提供两个保证,统称为Log Matching Property:
- 不同机器的日志中如果有两个
entry有相同的偏移和term号,那么它们存储相同的指令。 - 如果不同机器上的日志中有两个相同偏移和
term号的日志,那么日志中这个entry之前的所有entry保持一致。
假设图-6,如果Leader挂掉,然后第2个节点选举为Leader, 那么,第3和第5个节点就会出现日志丢失的情况。
因为节点2(leader)发送自己最新的日志条目给第3个节点,由于任期号匹配成功,但是index匹配不成功,此时第3个节点[3-x<-0]的就会丢失掉,这是非常危险的情况。如果这些日志条目已经committed了,状态是无法后退,只能前进,就会造成脏日志条目被某些节点提交的情况。
为了避免这些情况的发生,raft在节点进行选举的时候,候选人的日志条目必须不比比追随者的条目旧,追随者才会投票给当前的候选人,所以图-6中第2个节点是不会被选举为Leader的。
日志压缩
raft的日志压缩采用的是快照的方式。
快照是最简单的压缩方法。在快照系统中,整个系统的状态都以快照的形式写入到稳定的持久化存储中,然后到那个时间点之前的日志全部丢弃。快照技术被使用在 Chubby 和 ZooKeeper 中,接下来的章节会介绍 Raft 中的快照技术。
增量压缩的方法,例如日志清理或者日志结构合并树,都是可行的。这些方法每次只对一小部分数据进行操作,这样就分散了压缩的负载压力。首先,他们先选择一个已经积累的大量已经被删除或者被覆盖对象的区域,然后重写那个区域还活跃的对象,之后释放那个区域。和简单操作整个数据集合的快照相比,需要增加复杂的机制来实现。状态机可以实现 LSM tree 使用和快照相同的接口,但是日志清除方法就需要修改 Raft 了。
12:一个服务器用新的快照替换了从 1 到 5 的条目,快照值存储了当前的状态。快照中包含了最后的索引位置和任期号。
图 12 展示了 Raft 中快照的基础思想:
1 2 3 |
每个服务器独立的创建快照,只包括已经被提交的日志。主要的工作包括将状态机的状态写入到快照中。Raft 也包含一些少量的元数据到快照中:最后被包含索引指的是被快照取代的最后的条目在日志中的索引值(状态机最后应用的日志),最后被包含的任期指的是该条目的任期号。保留这些数据是为了支持快照前的第一个条目的附加日志请求时的一致性检查,因为这个条目需要最后的索引值和任期号。为了支持集群成员更新(第 6 节),***快照中也将最后的一次配置作为最后一个条目存下来***。一旦服务器完成一次快照,他就可以删除最后索引位置之前的所有日志和快照了。 尽管通常服务器都是独立的创建快照,但是领导人必须偶尔的发送快照给一些落后的跟随者。这通常发生在当领导人已经丢弃了下一条需要发送给跟随者的日志条目的时候。幸运的是这种情况不是常规操作:一个与领导人保持同步的跟随者通常都会有这个条目。然而一个运行非常缓慢的跟随者或者新加入集群的服务器(第 6 节)将不会有这个条目。这时让这个跟随者更新到最新的状态的方式就是通过网络把快照发送给他们。 |
安装快照 RPC:
在领导人发送快照给跟随者时使用到。领导人总是按顺序发送。
| 参数 | 解析 |
|---|---|
| term | 领导人的任期号 |
| leaderId | 领导人的 Id,以便于跟随者重定向请求 |
| lastIncludedIndex | 快照中包含的最后日志条目的索引值 |
| lastIncludedTerm | 快照中包含的最后日志条目的任期号 |
| offset | 分块在快照中的偏移量 |
| data[] | 原始数据 |
| done | 如果这是最后一个分块则为 true |
| 结果 | 解析 |
|---|---|
| term | 当前任期号,便于领导人更新自己 |
接收者实现:
- 如果term < currentTerm就理解回复
- 如果是第一个分块(offset 为 0)就创建一个新的快照
- 在指定偏移量写入数据
- 如果 done 是 false,则继续等待更多的数据
- 保存快照文件,丢弃索引值小于快照的日志
- 如果现存的日志拥有相同的最后任期号和索引值,则后面的数据继续保持
- 丢弃整个日志
- 使用快照重置状态机
在这种情况下领导人使用一种叫做安装快照的新的 RPC 来发送快照给太落后的跟随者;见图 13。当跟随者通过这种 RPC 接收到快照时,他必须自己决定对于已经存在的日志该如何处理。通常快照会包含没有在接收者日志中存在的信息。在这种情况下,跟随者直接丢弃他所有的日志;这些会被快照所取代,但是可能会和没有提交的日志产生冲突。如果接收到的快照是自己日志的前面部分(由于网络重传或者错误),那么被快照包含的条目将会被全部删除,但是快照之后的条目必须正确和保留。
这种快照的方式背离了 Raft 的强领导人原则,因为跟随者可以在不知道领导人情况下创建快照。但是我们认为这种背离是值得的。领导人的存在,是为了解决在达成一致性的时候的冲突,但是在创建快照的时候,一致性已经达成,这时不存在冲突了,所以没有领导人也是可以的。数据依然是从领导人传给跟随者,只是跟随者可以重新组织他们的数据了。
我们考虑过一种替代的基于领导人的快照方案,即只有领导人创建快照,然后发送给所有的跟随者。但是这样做有两个缺点。第一,发送快照会浪费网络带宽并且延缓了快照处理的时间。每个跟随者都已经拥有了所有产生快照需要的信息,而且很显然,自己从本地的状态中创建快照比通过网络接收别人发来的要经济。第二,领导人的实现会更加复杂。例如,领导人需要发送快照的同时并行的将新的日志条目发送给跟随者,这样才不会阻塞新的客户端请求。
还有两个问题影响了快照的性能。首先,服务器必须决定什么时候应该创建快照。如果快照创建的过于频繁,那么就会浪费大量的磁盘带宽和其他资源;如果创建快照频率太低,他就要承受耗尽存储容量的风险,同时也增加了从日志重建的时间。一个简单的策略就是当日志大小达到一个固定大小的时候就创建一次快照。如果这个阈值设置的显著大于期望的快照的大小,那么快照对磁盘压力的影响就会很小了。
第二个影响性能的问题就是写入快照需要花费显著的一段时间,并且我们还不希望影响到正常操作。解决方案是通过写时复制的技术,这样新的更新就可以被接收而不影响到快照。例如,具有函数式数据结构的状态机天然支持这样的功能。另外,操作系统的写时复制技术的支持(如 Linux 上的 fork)可以被用来创建完整的状态机的内存快照(我们的实现就是这样的)。