SFS Store 一种简单应用存储架构
Contents
sfs store 全称为simple file system store,是一个应用层存储系统的抽象,其接口类似于亚马逊的s3存储系统,对外全部提供http接口. 满足一般的中小型私有云存储业务。
sfs store 是一个对象存储系统,对象以kv的形式进行存储,每个对象的都有唯一标示,其唯一标示由bucket+key来区分,比如一个名为mvpic的bucket,其在sfs store中有一个对象,该对象的访问地址为http://www.mvpic.sfs.com/20193/axdffkasddd.jpg,那么这个对象的唯一标识为mvpic/20193/axdffkasddd.
bucket: 业务方的身份标识,如果一个用户注册一个bucket,那么在该bucket下面的所有文件都属于该用户所有。bucket除了可以标识对象所属空间,同时也可以作为对象的默认域名,比如:用户申请了一个mvpic的bucket,那么对象访问默认为:http://mvpic.sfs.com/key.ext,当然用户可以配置访问域名。
key: bucket下的文件唯一标识,也可以把一个文件抽象为一个对象,而该对象的唯一标示就是这个key。 在同一个bucket下,不会出现相同的对象,但是不同的bucket下对象是可以相同的,比如:”http://www.mvpic.sfs.com/20193/axdffkasddd.jpg" 和 “http://www.audio.sfs.com/20193/axdffkasddd.jpg" 虽然他们的key一样,都是20193/axdffkasddd,但是他们的bucket不一样,分别为mvpic和audio。
{kind=link}
{kind=link}
该系统主要有5个子系统,分别是*SFSUpload*、*SFSDownload*、*SFSTranscoder*、*SFSResource*、ImageRealTimeTranscoder
该系统以高可用、横向扩展为主
总体机构如下:
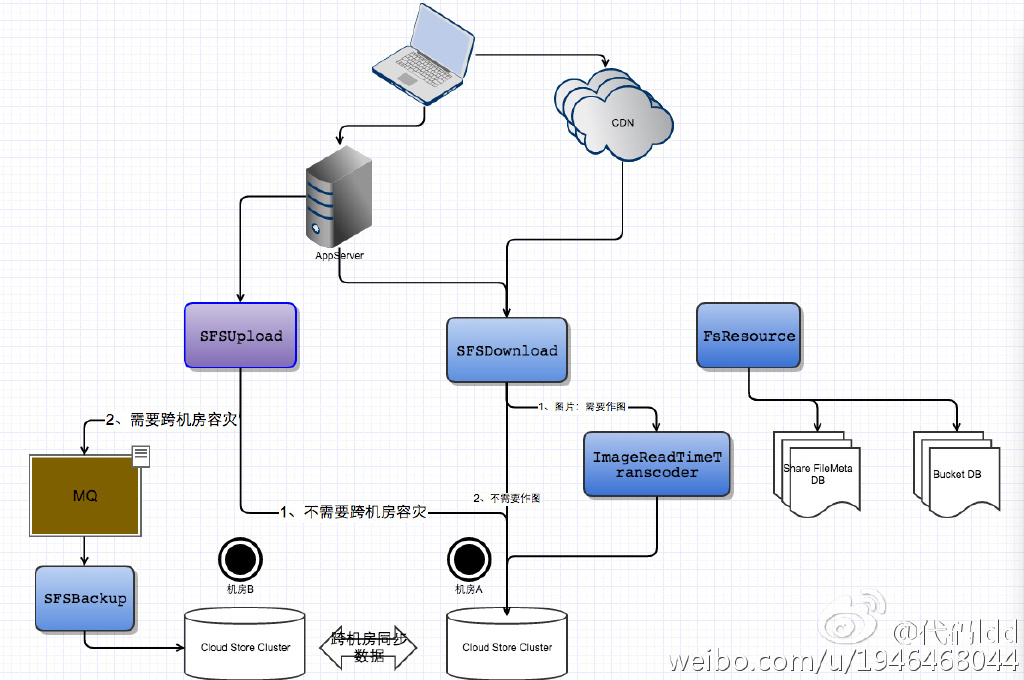
1. SFSUpload
SFSUplpad是控制文件上传调度的服务。
如:一个业务方需要上传一个文件,那么其上传的接口可简化表示为:
|
|
如果调用方没有指定该对象的key,那么服务也会自动生成一个key并返回给调用方,这个key的生成算法为:randKey=md5(bucket+timeStamp+value),则该对象的访问地址为http://bucketName.fs.kugou.com/randKey?kge=13123123&kgtoken=xxxxxxxxxxxxx
除此之外,SFSUpload还支持断点上传的逻辑。
SFSUpload断点上传
对于文件存储系统,断点续传是必不可少的,特别是在UGC业务中。为了提高断点上传的质量,一般断点上传都是分散部署的,也就是一个文件可以打散上传CDN,然后由CDN上传回到源站,这是一种比较典型的做法。既然是打散上传的,那么每一块文件就会落在不同的服务器上,为了能够整合这些分散的文件,记录每一块文件上传信息是必须的。一种简单的做法就是,当文件回源到服务端时,服务端会把相同的文件的不同块都转发到第一块所在的服务器上,第一块的服务器负者文件的上传纠正和文件的合成。
其架构可以简化为下图:
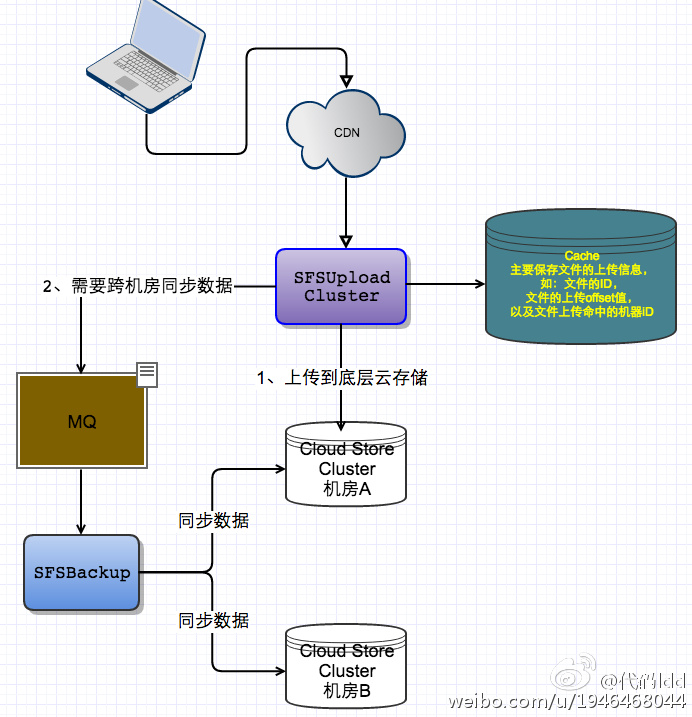
上传流程:
|
|
需要注意的地方以及需要说明的地方: 1、cache层是非重要的一个主键,应该要考虑容灾,因为一般的上传QPS都不会很高,所以cache 可采用Redis Sentinel架构,在每一台服务器机上服用部署即可 2、 如果是特别大的文件,源站上传到底层存储系统之间的链路也需要注意,按照本人的经验来说,期间出错的概率也是不少的。在源站到底层存储系统传输过程是非常耗时的,如果是客户端上传的话,在上传到最后一块时,其等待的时间出现超时的现象明显上升。如果可以的话,上传接口应该支持异步和同步操作,一般的UGC的业务可能都不会接受异步,他们更多的是想做到实时,如果是这样的话,可以考虑在源站服务器到底层存储系统之间做优化。比如,fastdfs文件存储系统,它是支持文件Append和Modify操作,这样,当客户端每上传一块文件,源站服务器应该就直接把该块的文件内容上传到fastdfs中去,其相应时间会得到大大的提高。 3、由于是文件的上传,所以对应用来说,需要注意一下内存和io相关的优化,比如使用内存储来降低内存的使用,如果是大文件的时候,还要考虑把使用带缓存区IO方式操作文件;在IO上需要注意一下文件的脏页影响,大量的更新、删除、新建文件必然会有造成这些负效应。 4、该架构的源站服务器满足横向扩展和高可用(当然源站服务器值保存一份数据,如果刚好该源站服务器挂了,那么只能重新上传了);cache支持高可用,但是暂时不支持横向扩展,可以考虑使用cache cluster模式来达到横向扩展的效果
5、文件上传后,需要根据bucket的属性来决定是否需要跨机房容灾,如果需要的话,
SFSUpload还需网同步队列发送同步数据的任务6、除此之外还需考虑“热点”问题,就是一个文件上传之后,应该马上放到
File CND Cache,如UGC文件以及聊天文件、直播图片等等,这种都是实时性强的业务,可以在上传的时候,加上一个是否马上缓存的Flag
2. SFSDownload、ImageRealTimeTranscoder
SFSDownload:访问调度服务,主要控制文件的访问调度和访问鉴权。
ImageRealTimeTranscoder:图片转码服务,负责图片的实时转码服务。
2.1 SFSDownload
2.1.1 AccessController
AccessController为访问的控制模块,主要用于检测token是否有效以及一些黑白名单的工作,比如:refer的过滤、非法ip过滤、防刷限流、访问域名限定等等。
其中bucket一般分为公有和私有,如果是公有的话,就不用带url token了,如果是私有的话,需要带url token,关于url token可参照如下的设计:
url分为永久和有时效性两种,所以url应该携带一个时效的参数,比如:sfstoken=e:key,其中e为一个时间戳参数,这个时间戳为该token下的url的有效访问时间,一旦时间超过,该url将不能再被访问,需要生产新的url。
其中token key生产算法可以简化为:SHA1(bucket+e+bucketSecretKey)
bucketSecretKey:云存储下发给用户的秘钥。
2.1.2 AccessDispatcher
AccessDispatcker为访问调度模块,AccessDispatcker首先会到golbal database获取到对象的所有下载连接,然后判断该文件类型是否为图片类型.
- 如果是图片类型且需要作图,那么以同步的方式,把下载连接和作图策略(如:等比缩略,缩略尺寸等信息)发给
ImageRealTimeTranscoder服务,ImageRealTimeTranscoder把作好的图返回给AccessDispatcher. - 如果不是图片类型,则马上到底层存储系统下载文件,把下载好的文件及时返回给客户端。
注意:
1、
global database可能会返回对个下载链接,因为这个对象为了容灾,可能不仅存储于一个集群中,可能存在在多个集群中,当然这些集群应该是跨机房。这时候,AccessDispatcker应该要选择最优的下载链接,如果这些链接都不是本机房的,可能还需要经过302跳转。2、SFSDownload的qps会比较高,这对象的元数据必须要缓存,并且缓存要做到横向扩中,还要考虑一下缓存失效的情况。
2.2.1 ImageRealTimeTranscoder
ImageReadlTimeTranscoder为图片实时作图服务,可采用imagemagick+lua+openresty这套成熟的方案。
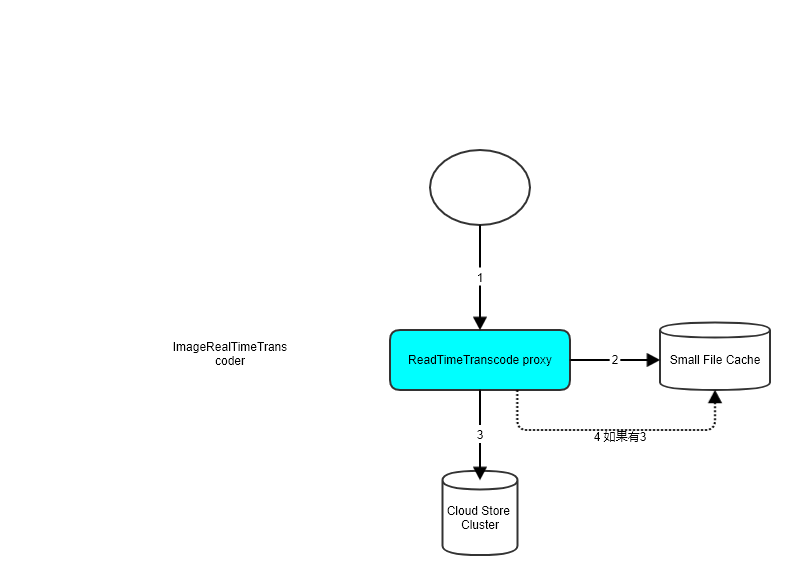
3. SFSTranscoder
SFSTranscoder为对象转码服务,一般音视频都需要转码,比如高低音频码率互转。
因为音视频转码是比较耗时的任务,一半采用异步转码即可,由应用服务发送转码任务到SFSTranscoder,SFSTranscoer采用生产者或消费者模式,具体架构如下:
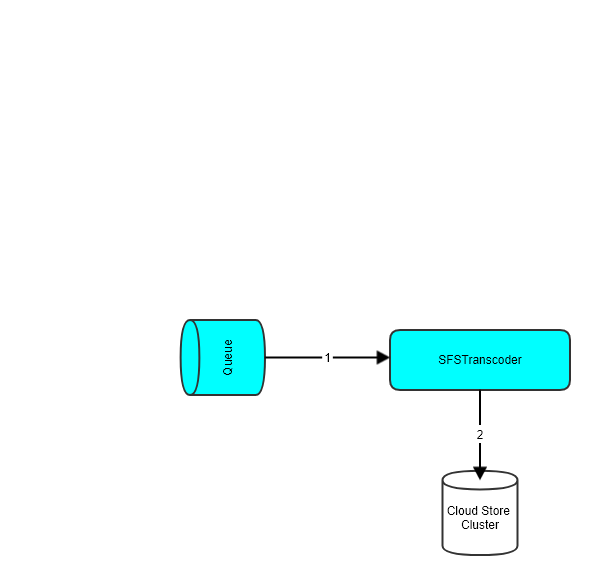
注意:
1、可以采用回调的模式来进行异步转码,也就是说应用服务器除了提供转码任务外,还需要提供一个转码成功后的回调地址,转码服务转码成功后,会把需要转码的对象key和转码后对象的key回调给应用服务器。
2、如果有必要,也需要提供一个转码进度的查询接口。
4. SFSResource
SFSResource :云存储管理服务,主要负责对象的管理,比如:删除对象、屏蔽对象、删除bucket、增加bucket、增加bucket的下载域名、现在bucket的上传容量以及对象大小、清理缓存等等任务.
5. Meta Data
Meta Data:对象元数据存储。
- 水平扩容
- 跨机房容灾、同步
5.1 Meta Data Design
- t_obj_id
| 字段名 | 字段类型 | 说明 |
|---|---|---|
| bucket | string | 业务空间 |
| key | string | 对象id |
- t_bucket_info
| 字段名 | 字段类型 | 业务空间 |
|---|---|---|
| bucket | string | 业务空间 |
| domain | string | 空间访问域名,以逗号分隔,如:mvpic-sfs.com,mvpic2-sfs.com |
| access | string | 空间访问属性 |
| cluster_ids | string | 底层存储集群id,表示可以空间可以使用的存储集群编号。 |
| total | int | 空间容量最大值 |
- t_obj_info
| 字段名 | 字段类型 | 字段说明 |
|---|---|---|
| obj_id | string | 对象唯一id,SHA1(bucket+key) |
| edit_time | string | 对象更新时间 |
| extend_name | string | 对象后缀属性 |
| size | int64 | 对象大小 |
| access | string | 对象访问属性 |
| mime | string | 对象媒体属性 |
| obj_md5 | string | 对象的内容md5值 |
| obj_store_id | string | 对象的实际存储路径,可能有多个,以逗号区分,如:clusterid/bucket/key:clustered/bucketid/key |
- t_cluster_info
| 字段名 | 字段类型 | |
|---|---|---|
| cluster_id | int | 底层存储的集群id |
| cluster_type | string | 比如:tfs 、fastdfs |
| flag | uint8 | bitmap类型:x❌x❌x:可写:可读,暂时使用最后两位 |
6. File Store
File Store即底层存储服务,也是图片中的Cloud Store, 目前市面上用得比较多的开源文件存储是:Ceph、Fastdfs、TFS。
- 横向扩展
- 跨机房容灾、同步
7. Summary
- 这种底层容灾方案有点复杂了,一般公司更多的是做成集中式存储,也就是说所有的对象存储是同等对待的,要么全部都跨机房存储,要么就单边存储。这种集中式存储架构设计和存储部署都更加简单,更加容易维护。就是扩展性没那么强,灵活性不够。
- 为了易于排查文件,最好服务器之间调用带上请求
id,这样可以快定位到问题。 - 为了防止数据同步时的数据丢失,
MQ最好选用可持久化、可回溯且支持多机模式的消息队列系统,如:Kafka或者RabittMQ。 - 应用服务器的配置会变得非常多,特别在增加集群是,很多配置都会受到影响,可以考虑使用分布式配置系统,如:
zk、etcd、consol等等。 - 如果对性能要求比较高,服务之间可以是用
rpc方式调用,而不是是http dns的方式,dns控制也不灵活,有时候可能得找运维才能下线出错的机器,这样灾难恢复时间过长了。