使用Golang语言实现一个简单的Bitcask引擎的文件存储系统
Contents
bitcask是bashro的设计的一个底层存储引擎,主要应用于Riak产品中(ps:国内的beansdb的底层存储引擎也是使用bitcask,分布式上也是使用dynamo,并且他们也根据自己的实际应用做了相应的优化),其设计简单易懂,算法也是很简明的算法。其存储对象类型是key/value类型。

talk is cheap, show me the code! 设计模型以及特点
- 所有的
key都存储于内存中;所有的value都存储于磁盘中 - 以追加的方式写磁盘,即写操作是有序的,这样可以减少磁磁盘的寻道时间,是一种高吞吐量的写入方案,在更新数据时,也是把新数据追加到文件的后面,然后更新一下数据的文件指针映射即可
- 读取数据时,通过数据的指针以及偏移量即可,时间复杂度为
O(1),因为所有key都是存储于内存中,查找数据时,不用检索磁盘文件,这大大减少了检索时间 bitcask有一个合并的时间窗口,当旧数据站到一定比例时,会触发合并操作,同时为了设计更简单,会把旧数据重新追加到可写文件中(riak里面的合并策略跟多,具体的合并策略可以去看它的源码)(ps:虽然自己实现了这个操作,但是还在测试阶段,应该有潜在的Debug,如果哪位有对这个项目有兴起,可以修复一下)
具体的组件设计图
bitcask的数据文件分为只读文件和唯一一个读写文件
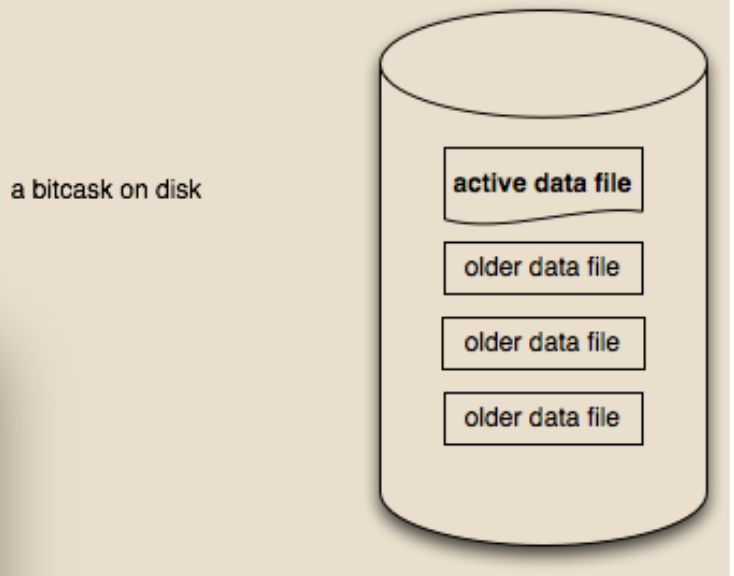
为了加快索引的重建速度,每个数据文件对应一个hint文件,如:

data文件的格式如下:
1
|
crc32(4byte)|tStamp(4byte)|ksz(4byte)|valueSz(4byte)|key|value |
这样通过key的大小和value的大小就可以找到key的位置和value的文件,但是如果bitcask重启后,直接扫描data文件来建立索引是一件非常耗时的工作,这时候hint文件就派上场了,hint文件格式如下:
1
|
tstamp(4byte)|ksz(4byte)|valuesz(4byte)|valuePos(8byte)|key |
这样在可以跳过value的扫描,扫描速度自然就起来了,通过valuePos就可以直接找到文件的内容。
数据结构的设计
文件映射的结构体
type BFile struct
|
|
fp指向Active data file, fileID表示Active data file的文件名,hintFp表示Active hint file
type BFiles struct
|
|
bfs每一项表示一个文件索引项,直接使用map来存储不是一个高效的方法,以后再优化吧…
key/value结构体
type entry struct
|
|
该结是hint文件的映射,fileID为data的文件名,valueSz表示值的大小,valueOffset表示value在data文件的索引位置,timeStamp表示value的存储时间(这个存储时间是会变的,因为在merge的时候,旧的数据会重新追加到Active文件中,这样这些旧的数据会重新洗牌,变成新的数据).
type KeyDirs struct
|
|
这个结构是主要的占内存的地方,因为所有key都存储于此,这个结构体由hint文件构建的.
这个结构体也是后续需要优化的地方,比如:fileID很多是相同的,可以将他们存储在一个数组中,entry只要存储数组的fileID索引即可。
type BitCask struct
|
|
bitcask是最重要的结构体,是程序的入口,oldFile是只读文件的索引;writeFile是Active file的索引;keyDirs是key的索引。
关于Merge
为了节省空间,bitcask采用merge的方式剔除脏数据,merge期间会影响到服务的访问,merge是一件消耗disk io时间,用户应该错开merge的io高峰期.其中merge的触发也有很多种(触发不一定就会执行),如:
- 定时策略
用户自定义触发merge的时间
- 间隔策略
每隔一定的时间触发merge事件
其他等等…..
当merge时间触发时,bitcask就会根据用户自定的策略去决定是否执行merge操作,merge执行策略如:
- 定时策略
在用户定义的时间内执行merge操作,该操作会损耗服务的能力,用户应该避免高峰期,在低峰期时才执行该操作
- 容量策略
当胀数据达到一定的比例或者大小时,执行merge操作
其他的等等……
如何实现一个简单的Merge:
为简化设计,便于实现,merge操作把需要的old file文件重新扫描,如果记录是老的或者被删除了得,就过滤掉;需要保留的就按正常的操作重新插入到active file文件中。
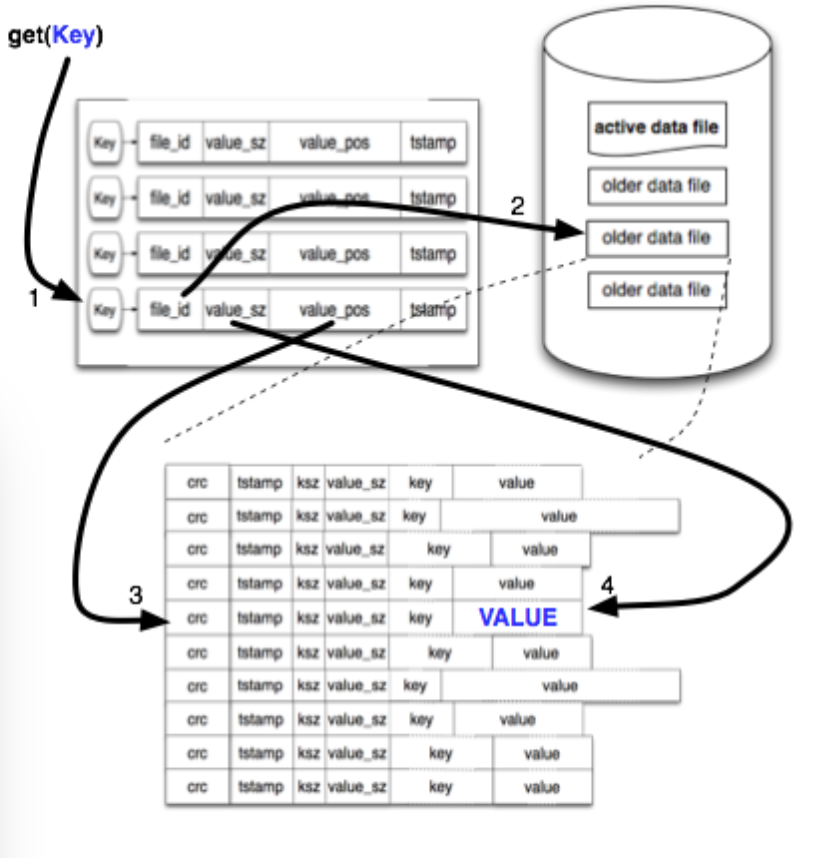
(ps:本人只实现了一个简单的merge操作,由于比较忙,优化和策略方面还没全面)
TODO LIST
- 优化hashmap
- 增加多种合并策略
- 减少锁的颗粒度
简单的操作
|
|
|
|