erlang 之简单的Diction实现
最近在看学erlang ,看到了字典这个demo ,把程序Copy出来和大家分享一下
-module (diction).
-export([new/0,lookup/2,add/3,delete/2]).
new() ->
[].
lookup(Key , [{Key,Value}|Rest]) ->
{value,Value};
lookup(Key,[Pair|Rest]) ->
lookup(Key,Rest);
lookup(Key,[]) ->
undefined.
add(Key,Value,Diction) ->
NewDict = delete(Key,Diction) ,
[{Key,Value}|NewDict].
delete(Key,[{Key,Value}|Rest]) ->
Rest;
delete(Key,[Pair|Rest]) ->
[Pair|delete(Key,Rest)];
delete(Key,[]) ->
[].
函数编程习惯之后,写起来也是挺爽的意见事,基本上都是递归的思想。
erlang 之简单密码加密
这些程序主要是来之 连城 翻译的一个书里面的代码
-module(encode).
-export([encode/2]).
encode(Pin.Password) ->
Code = {nil,nil,nil,nil,nil,nil,nil,nil,nil,
nil,nil,nil,nil,nil,nil,nil,nil,nil,
nil,nil,nil,nil,nil,nil,nil,nil},
encode(Pin,Password,Code).
encode([],_,Code) ->
Code ;
encode(Pin,[],code) ->
io:format("Out of Letters~n",[]);
encode(H|T,[Letter|T1],Code) ->
Arg = index(Letter) +1 ,
case element(Arg,Code) of
nil ->
encode (T,T1,setelement(Arg,Code,index(H)));
_->
encode ([H|T],T1,Code)
end.
index(X) when X >= $0 ,X =< $9 ->
X - $0;
index(X) when X>=$A , X =< $Z ->
X - $A.
erlang 简单的树操作
-module(tree).
-export([test1/0]).
lookup(Key,nil) ->
not_found;
lookup(Key,{Key,Value,_,_}) ->
{found,Value};
lookup(Key,{Key1,_,Smaller,_}) when Key < Key1 ->
lookup(Key,Smaller);
lookup(Key,{Key1,_,_,Bigger}) when Key > Key1 ->
lookup(Key,Bigger).
insert(Key,Value ,nil) ->
{Key,Value,nil,nil};
insert(Key,Value,{Key,_,Smaller,Bigger}) ->
{Key,Value,Smaller,Bigger} ;
insert(Key,Value,{Key1,V,Smaller,Bigger}) when Key < Key1 ->
{Key1,V,insert(Key,Value,Smaller),Bigger};
insert(Key,Value,{Key1,V,Smaller,Bigger}) when Key > Key1 ->
{Key1,V,Smaller,insert(Key,Value,Bigger)}.
write_tree(T) ->
write_tree(0,T).
write_tree(D,nil) ->
io:tab(D),
io:format('nil',[]);
write_tree(D,{Key,Value,Smaller,Bigger}) ->
D1 = D +4 ,
write_tree(D1,Bigger),
io:format('~n',[]),
io:tab(D),
io:format('~w ==> ~w~n',[Key,Value]),
write_tree(D1,Smaller).
test1() ->
S1=nil,
S2=insert(4,joe,S1),
S3=insert(12,fred,S2),
S4=insert(3,jane,S3),
S5=insert(7,kalle,S4),
S6=insert(6,thomes,S5),
S7=insert(5,rickard,S6),
S8=insert(9,susan,S7),
S9=insert(2,tobbe,S8),
S10=insert(8,dan,S9),
write_tree(S10).
代码不多,erlang写算法……呵呵呵呵呵呵
erlang 并发编程
最近上班比较忙,没时间学习erlang ,实在对不起自己啊,以前一直在找erlang相关的教程,终于找到一个了,这个网站是前几天才开始运行的,以后的文章可能都是来自于那里,网站是http://www.erlang-cn.com ,大家忙没事多学习!大笑
- 并发编程一
-module(tut15).
-export([start/0,ping/2,pong/0]).
ping(0,Pong_PID) ->
%%想对方发送退出信号
Pong_PID ! finished,
io:format("ping finished~n",Pong_PID);
ping(N,Pong_PID) ->
Pong_PID ! {ping,self()},
receive
pong ->
io:format("Ping receive pong ~n",[])
end,
%%继续接受信息,直到 N == 0
ping(N-1,Pong_PID).
pong() ->
receive
finished ->
io:format("Pong finished~n",[]);
{ping,Ping_PID} ->
io:format("Pong received ping ~n",[]),
Ping_PID!pong,
%%再次等待对方的信息,直到信息为ffinished
pong()
end.
start() ->
%% 开启一个进程,用来等待其他进程的信息
Pong_PID = spawn(tut15,pong,[]),
%%开启一个进程,用来发送信息
spawn(tut15,ping,[3,Pong_PID]),
io:format("Main Process Exit~n",[]).
进程的标识 ,我们还有一种更加灵活的方法来标记她那就是使用register函数
-module(tut16).
-export([start/0,ping/1,pong/0]).
ping(0) ->
pong ! finished,
io:format("ping finished ~n",[]);
ping(N) ->
%% send the message to pong proccess
pong ! {ping,self()},
receive
pong ->
io:format("Ping received pong ~n",[])
end ,
ping(N-1).
pong() ->
receive
finished ->
io:format("Pong finished~n",[]);
{ping,Ping_PID} ->
io:format("Pong received ping~n",[]),
Ping_PID ! pong,
pong()
end.
start() ->
register(pong,spawn(tut16,pong,[])),
spawn(tut16,ping,[3]).
register中的pong就标识了spawn(tut16,pong,[])这个进程,这个ping()函数只要一个N就行了,pong可以看作是进程之间共享的变量.
erlang 之 echo 服务器
简单实现了一个echo 服务器
- echo_server1
-module(echo).
-export([start/0,loop/0]).
start() ->
Pid = spawn(echo,loop,[]),
Pid ! {self(),'Hello Word'},
receive
{Pid,Msg} ->
io:format('~w~n',[Msg])
end,
Pid ! stop.
loop() ->
receive
{FromOther,Msg} ->
io:format("~w~n",[Msg]),
FromOther!{self(),'Loop Proccess Send to You !'},
loop();
{stop} ->
%%io:format('~w~n',[loop_stop]),
true
end.
Output:
29> echo:start().
'Hello Word'
'Loop Proccess Send to You !'
stop
30>
其中 stop 是主进程的返回值
- echo_server2
这是一个简单用于等待外部信息的echo server
-module(echo_server).
-export([start/0,print/1,stop/0,loop/0]).
start() ->
Pid = spawn(echo_server , loop , []),
register(sub1,Pid),
{ok,Pid}.
loop() ->
receive
{print,A} ->
io:format("~p.~n",[A]),
loop();
stop ->
true;
Other ->
io:format("~p~n",[Other]),
loop()
end.
print(A) ->
sub1 ! {print,A},
true .
stop() ->
sub1 ! stop ,
%%
true .
timeout 的简单使用
今天晚上有点晚了,不过还是坚持每一天写一个程序!
下面的时超时器 :
建设A要想db进程发送一个信息,然后在规定的时间内等待消息的返回,那么A可以设置一个超时器,注意的是在发送消息之前,得先清空消息队列,要不然等译接到的消息可能db还没发送之前的了.
read(Key) ->
flush(),
db | {self(),{read,Key}},
receive
{read,R} -> {ok,R};
{error,Reason} -> {error,Reason}
after 1000 -> {error,timeout}
end.
flush() ->
receive
{read,_} -> flush();
{error,_} ->flush()
after 0 ->ok
end.
Erlang进程生成测试
-module(myring).
-export([start/1,start_proc/2]).
start(Num) ->
start_proc(Num,self()).
start_proc(0,Pid) ->
receive
ok -> ok
end,
Pid ! ok ;
start_proc(Num,Pid) ->
NPid = spawn(?MODULE,start_proc ,[Num-1,Pid]),
NPid ! ok ,
receive
ok -> ok ,
io:format("~w~n",[Num])
end.
进程退出时会返回ok。
erlang之时钟
今天来看一下erlang中的时钟如何实现的:
-module(timeout).
-export([sleep/1,flush_buffer/0]).
%%%睡眠函数
sleep(Time) ->
receive
after Time ->
true
end.
%%%清空邮箱
flush_buffer() ->
receive
AnyMessage ->
flush_buffer()
after 0 ->
true
end.
%%% 消息优先级的实现
%% 函数priority_receive会返回邮箱中第一个消息,除非有消息interrupt发送到了邮箱中,此时将返
%%回interrupt。通过首先使用超时时长0来调用receive去匹配interrupt,我们可以检查邮箱中是否已经有了
%%%这个消息。如果是,我们就返回它,否则,我们再通过模式AnyMessage去调用receive,这将选中邮箱中的
%%第一条消息。
priority_receive() ->
receive
interrupt ->
interrupt
after 0 ->
receive
AnyMessage ->
AnyMessage
end
end.
上面主要是睡眠 和清空“邮箱” ,还有就是优先级的简单实现.
下面再来一段吧:
-module(timer).
-export([timeout/2,cancel/1,timer/3]).
timeout(Time,Alarm) ->
spawn(timer,timer,[self(),Time,Alarm]).
cancel(Timer) ->
Timer ! {self(),cancel}.
timer(Pid,Time,Alarm) ->
receive
{Pid,cancel} ->
true
after Time ->
Pid ! Alarm
end.
shell中演示一下:
13> Pid=self(),
13> timer:timer(Pid,1000,hellword).
hellword
14>
a simple erlang process pool analysis
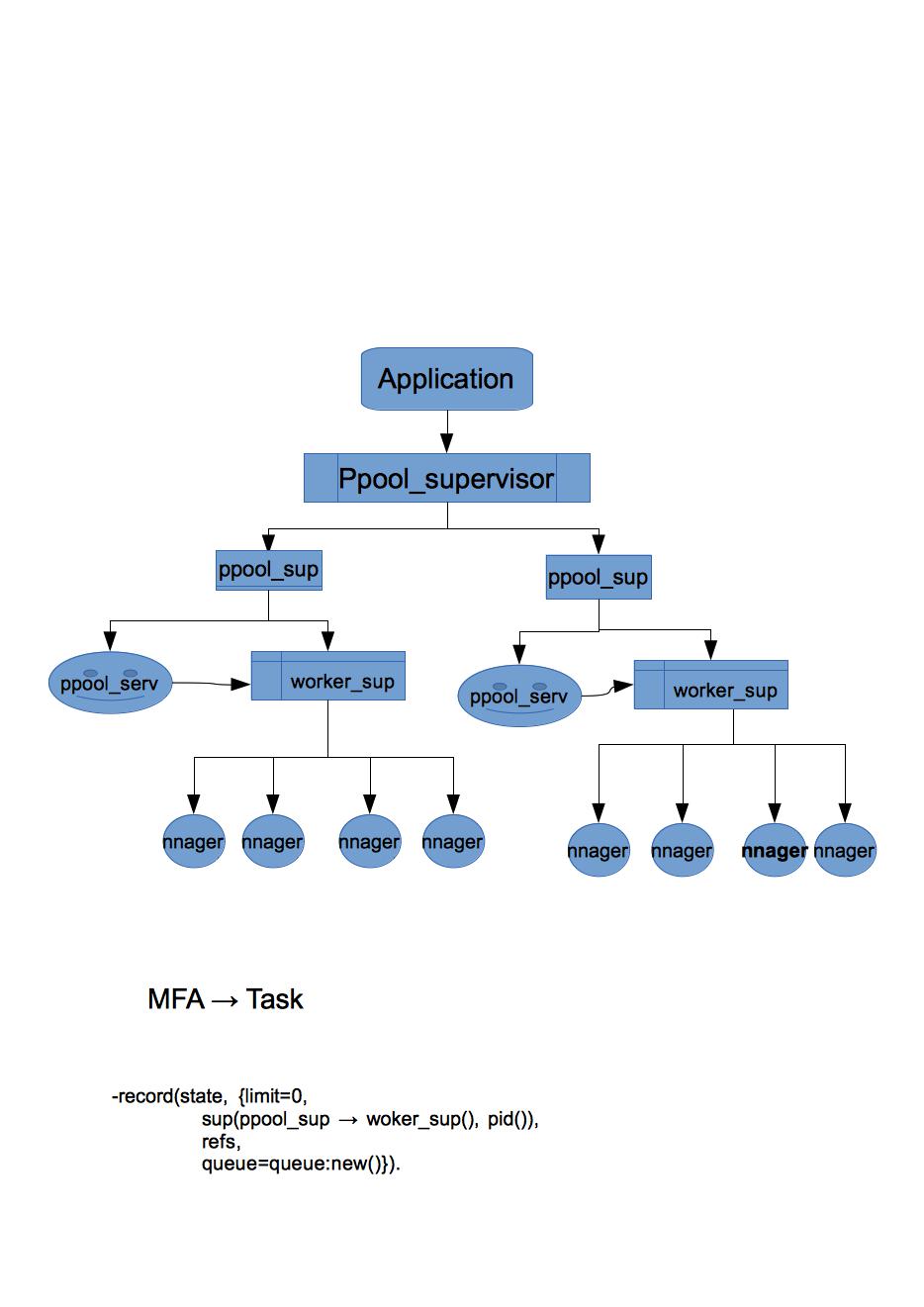
这是一个简单的erlang进程池分析,是learn you some erlang for Great Good里面的一个example,详细的内容可到官网查看!
- 实现原理
这个的例子的实现原理官网都有比较详细的说明,主要模块在ppool_serv中,ppool_serv是一个gen_server behaviour, 而ppool_sup是一个one_for_all的策略,如果ppool_serv或者worker_sup出现问题,彼此也没有存在的必要了。
这里ppool_serv和worker_sup的实现,使用了一个简单的技巧,因为worker_sup不是ppool_sup直接调用生成的,它是由ppool_serv控制生成的:
%% Gen server
init({Limit, MFA, Sup}) ->
%% We need to find the Pid of the worker supervisor from here,
%% but alas, this would be calling the supervisor while it waits for us!
self() ! {start_worker_supervisor, Sup, MFA},
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
woker_sup由ppool_serv自己在init函数中,发给自己一个Message,然后在回调函数中才生成:
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
link(Pid),
{noreply, S#state{sup=Pid}};
如果他们一起直接生产,那么会产生死锁,
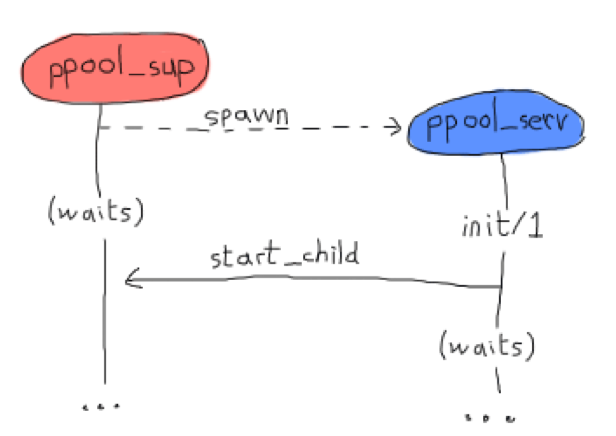
当然,他这里的生成顺序,可以自己修改一下,也不会出现死锁。
gen_serv的主要数据结构
-define(SPEC(MFA),
{worker_sup,
{ppool_worker_sup, start_link, [MFA]},
temporary,
10000,
supervisor,
[ppool_worker_sup]}).
-record(state, {limit=0,
sup,
refs,
queue=queue:new()}).
?SPEC(MFA), 这里的MFA指明一类Task,所以同一个ppool_worker_sup,不会有不同类型的Task,它的策略也是simple_one_for_one.
在这个例子中,使用了一个gen_server -- nnager module作为Task,这个Task的参数为:{Task, Delay, Max, SendTo}, Task标示任务名字,Delay作为超时时间,只是标示这个任务是有超时限制的,也是一个调试技巧,Max为最大超时次数,SendTo用来发送信息给回调进程,这个进程可以是shell, 如果是shell,flush()就会收到信息。
record用来标识一些主要的信息,Limit为进程池的大小限制,sup开始为ppool_sup的pid(),在生成woker_sup进程后,就变成worker_sup的进程pid(),因为ppool_serv的主要交流对象还是worker_sup和worker(Task); refs(gb_set)为woker的进程链接,这样可以在worker进程down掉或者done时,从线程池中剔除掉;queue为任务队列,当任务大于limit时,就把多余的任务放到queque中,等到进程池有空闲时,就从中pop出任务,接着处理。
这里有些局限的地方:
- 每次的任务都是新建的进程去处理,就是说进程的生命周期跟任务的生命周期是一样的,可以把进程跟任务分离出来,让进程不随任务的结束而结束(当然这的任务就不要是gen_server,gen_fsm这些,因为这些也是spawn出来的进程),这样进程开销理论上一次初始化就行了,虽然进程在erlang中开销比较少;
- 队列没有大小限制
PoolBoy
source code :
https://github.com/devinus/poolboy
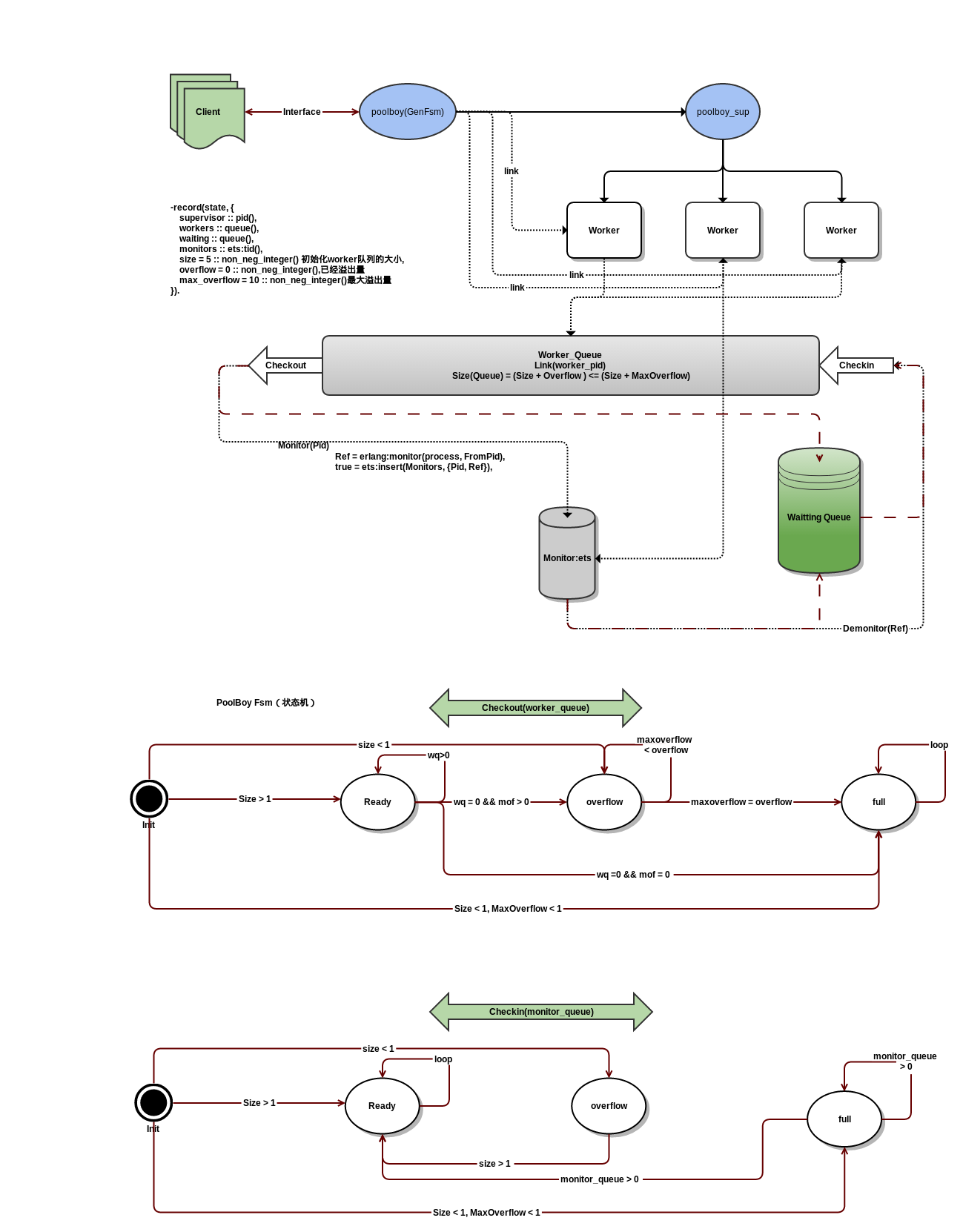
- Checkout
ready({checkout, Block, Timeout}, {FromPid, _}=From, State) ->
#state{supervisor = Sup,
workers = Workers,
monitors = Monitors,
max_overflow = MaxOverflow} = State,
case queue:out(Workers) of
{{value, Pid}, Left} ->
Ref = erlang:monitor(process, FromPid),
true = ets:insert(Monitors, {Pid, Ref}),
NextState = case queue:is_empty(Left) of
true when MaxOverflow < 1 -> full;
true -> overflow;
false -> ready
end,
{reply, Pid, NextState, State#state{workers=Left}};
{empty, Empty} when MaxOverflow > 0 ->
{Pid, Ref} = new_worker(Sup, FromPid),
true = ets:insert(Monitors, {Pid, Ref}),
{reply, Pid, overflow, State#state{workers=Empty, overflow=1}};
{empty, Empty} when Block =:= false ->
{reply, full, full, State#state{workers=Empty}};
{empty, Empty} ->
Waiting = add_waiting(From, Timeout, State#state.waiting),
{next_state, full, State#state{workers=Empty, waiting=Waiting}}
end;
Checkout出一个worker从worker Queue中,如果有,则monitor(ets)这个worker,然后根据队列的容量和MaxOverflow的值来确定下一状态为full,overflow,ready (ready + overflow <= full);如果没有,而MaxOverFlow的值大于0,则新建一个worker,并将其加入monitor,最后重置状态项worker = empty, overflow = 1;如果没有,并且MaxOverflow 小于1, Block == false,则{reply, full, full, State#state{workers=Empty}};如过没有,MaxOverflow < 1, Block == true,则 {next_state, full, State#state{workers=Empty, waiting=Waiting}}。
- Checkin
ready({checkin, Pid}, State) ->
Monitors = State#state.monitors,
case ets:lookup(Monitors, Pid) of
[{Pid, Ref}] ->
true = erlang:demonitor(Ref),
true = ets:delete(Monitors, Pid),
Workers = queue:in(Pid, State#state.workers),
{next_state, ready, State#state{workers=Workers}};
[] ->
{next_state, ready, State}
end;
从Monitor中剔除对应的worker,然后回收到worker queue中去。
状态转变
- 状态转变的计算:
worker_queue_size(当前size) + maxoverflow 。
ready只与当前worker_queque_size有关,overflow 和worker_queue_size(0)和maxoverflow>0有关,full和work_queue_size(0), overfllow = maxoverflow有关。
- worker的来源
所有的worker要么在初始化时创建平;要么调用checkout时,经过poolboy创建,但此时创建的worker没有进到worker queue,要想进到worker queue,只能调用checkin。
work pid 回收到worker_queue中
checkin_while_full --》{empty, Empty} when MaxOverflow < 1 ->;