View
GoMap实际上就是一个hashTable,数据存储在数组buckets中。每个bucket包含 8 个键值对。hash的低8位用于映射bucket,在bucket内,使用hash的剩下的高位用于区分。
如果超过8个键被hash到某个bucket,需要连接到额外的buckets。
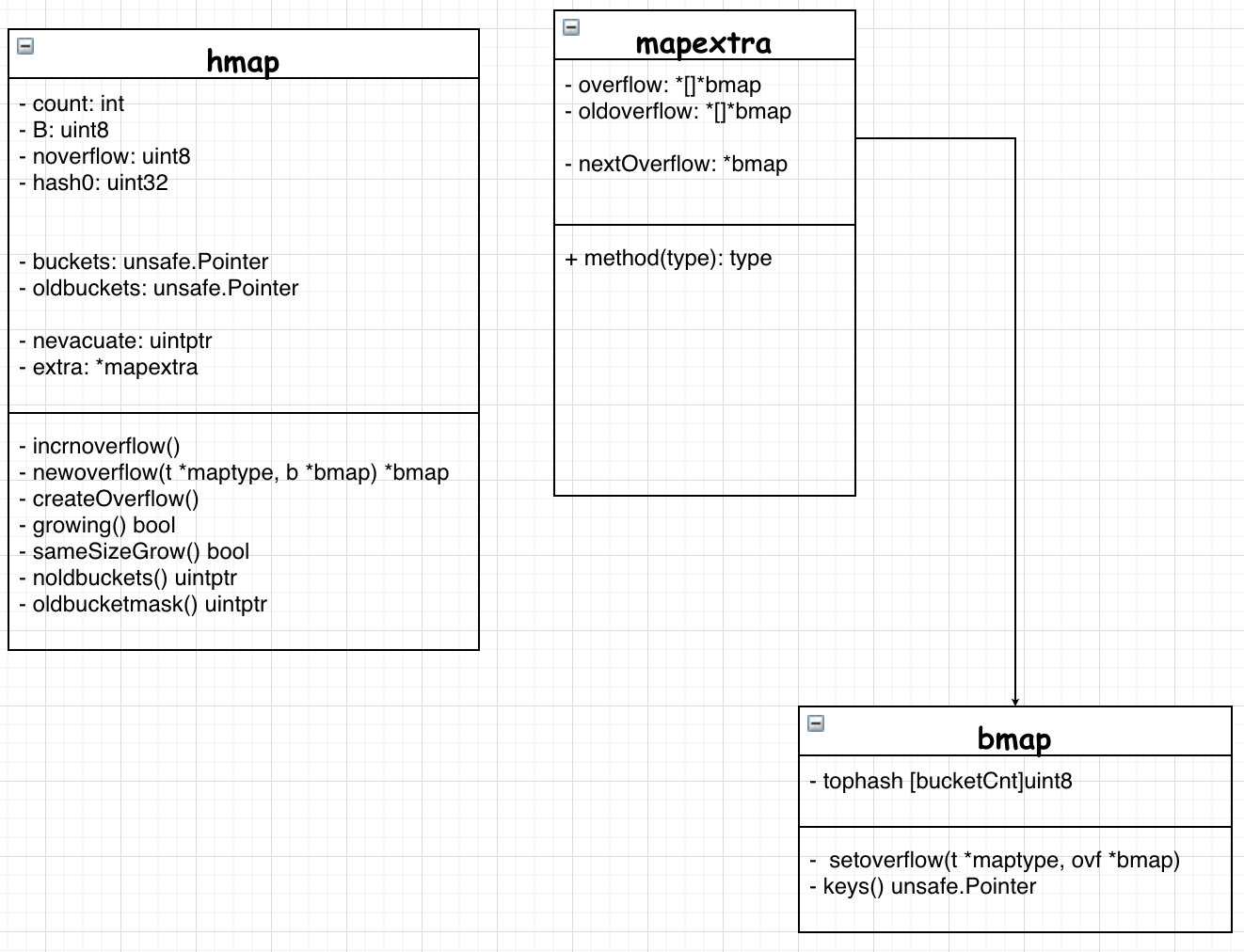
hmap.B 可容纳的键值对: *2^B*;hmap.bucketSize: 每个桶的大小;hmap.buckets: 2^B Buckets的数组;hmap.oldbuckets: 旧桶,在迁移时不为空;nevacuate:迁移进度;extra:?
比如有这么一个hashmap:
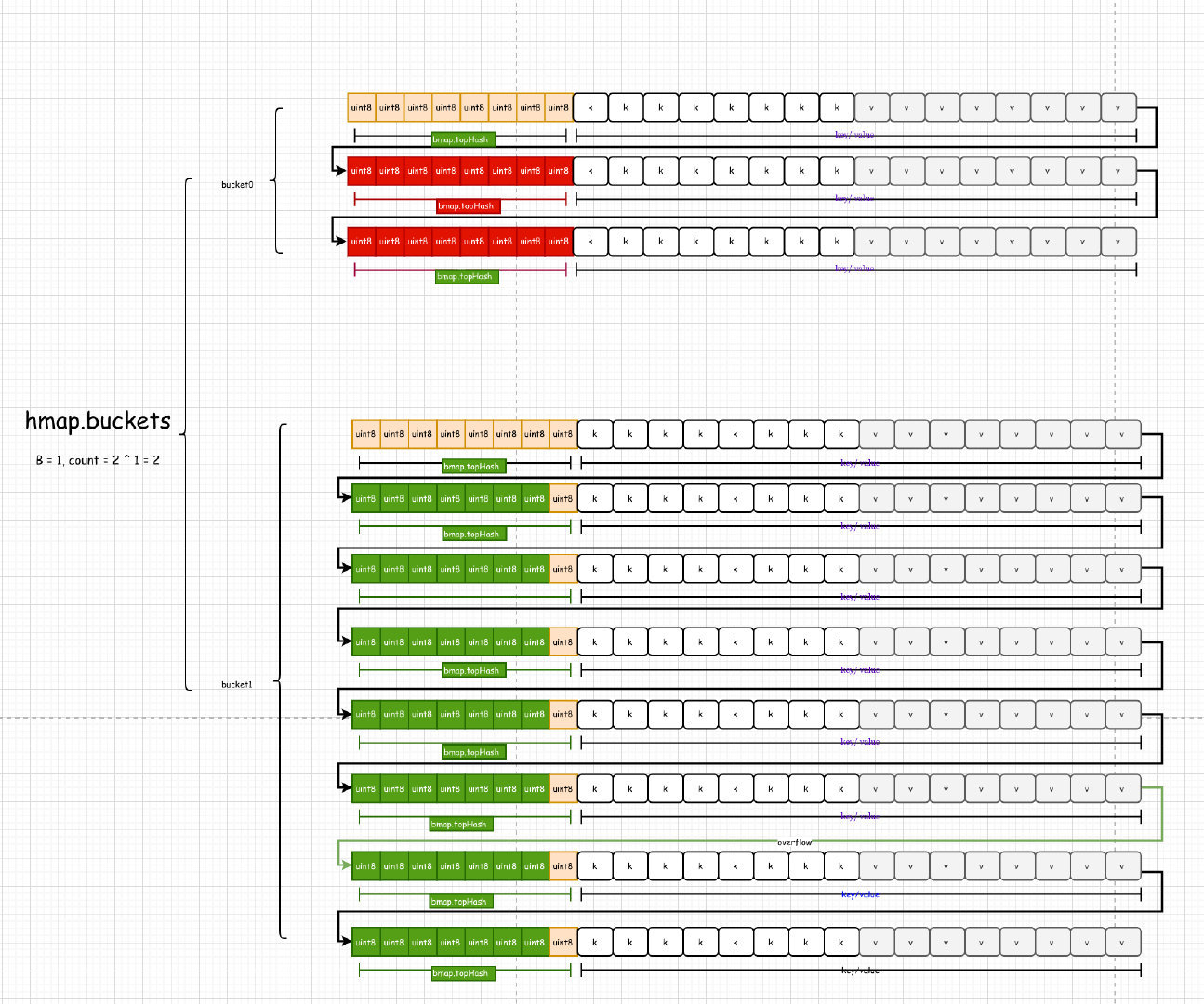
*注*:
1:为了避免字节对齐带来的空间浪费,键值对的存储并不是键/值/键/值这种方式,而是键/键/值/值的方式。
2:如果键值存储的是指针会加重gc的扫描(指针需要扫描指针指引的对象,可能会一直迭代扫描下去),如果不是指针,那么一一迭代扫描了。
Init Map
1
2
3
|
if hint < 0 || hint > int(maxSliceCap(t.bucket.size)) {
hint = 0
}
|
1
2
3
4
|
if h == nil {
h = (*hmap)(newobject(t.hmap))
}
h.hash0 = fastrand()
|
注: 为了安全(加入随机因子),不停的迭代,可以看出每个new map,他们随机因子都是不同的,而且getg().m应该每次启动都不同的(TODO:找出更多细节).
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func fastrand() uint32 {
mp := getg().m
// Implement xorshift64+: 2 32-bit xorshift sequences added together.
// Shift triplet [17,7,16] was calculated as indicated in Marsaglia's
// Xorshift paper: https://www.jstatsoft.org/article/view/v008i14/xorshift.pdf
// This generator passes the SmallCrush suite, part of TestU01 framework:
// http://simul.iro.umontreal.ca/testu01/tu01.html
s1, s0 := mp.fastrand[0], mp.fastrand[1]
s1 ^= s1 << 17
s1 = s1 ^ s0 ^ s1>>7 ^ s0>>16
mp.fastrand[0], mp.fastrand[1] = s0, s1
return s0 + s1
}
|
1
2
3
4
5
6
7
8
9
|
// find size parameter which will hold the requested # of elements
B := uint8(0)
// 计算一个合适的负载因子
// 主要是loadFactorNum*(bucketShift(B)/loadFactorDen))
// bucketShift(B) * loadFactorNum/loadFactorDen
for overLoadFactor(hint, B) {
B++
}
h.B = B
|
1
2
3
4
5
6
7
8
|
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
|
1: 如果B=0,则采用懒惰分配策略
2: nextOverflow: 下一个空闲的起止位置。什么意思呢?
2.1 bucekt => |bmap1|bmap2|bmap3|overflow-bmap
其中overflow-bmap为最后bmap3的溢出区overflow-bmap,那么下一调用map.newoverflow(t *maptype, b *bmap) 时相当于提前生成了nextOverflow
2.1 bucket => |bmap1|bmap2|bmap3
无溢出,nextOverflow自然为nil
*注*:如果初始化时,nextflow不为nil,则其布局如下:

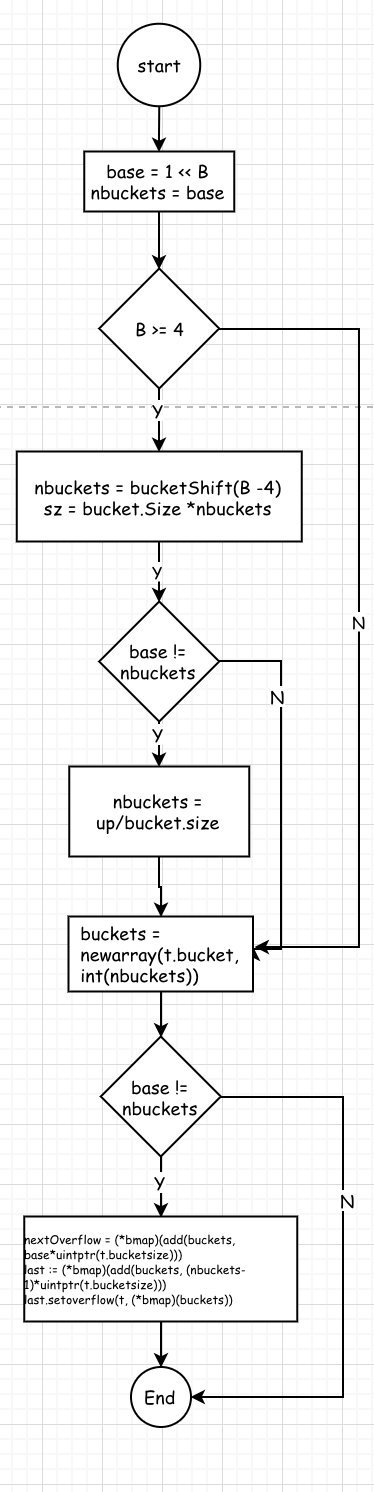
注: 内存分配是要涉及到页对齐,所以nbuckets可能会比base大,这时候会预分配 nbuckets - base 个 nextOverflow桶
Lookups
1
2
|
v := m["key"] --> runtime.mapaccess1(m, "key", &v)
v, ok := m["key"] --> runtime.mapaccess2(m, "key", &v, &ok) |
mapaccess1、mapaccess2、mapaccess3大同小异,分析mapaccess1即可。
1
2
3
4
|
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B) //
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
|
1
2
3
4
5
6
7
8
9
10
|
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
// tophash calculates the tophash value for hash.
func tophash(hash uintptr) uint8 {
// 往右移,剩下高8位,即top为hash的高8位
top := uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
// 小于minTopHash时,需要加上minTopHash,[0, minToHash]已被占
// 用,假设top =1, top+=minTopHash = 5. 如果topHash1 = 5,
// 最终结果topHash = topHash1,这样也不影响后续的比较(if alg.equal(key, k))
top += minTopHash
}
return top
}
|
存储高8位,简单的加速检索策略。
Insert
1
|
m["key"] = 8120 --> runtime.mapinsert(m, "key", 8120)
|
源码函数:mapassign(t *maptype, h *hmap, key unsafe.Pointer)
- 计算桶位置
- 检查oldBuckets是否为空,不为空,则增量迁移
- 迭代桶和溢出桶,查找目标,查到则更新对应的值;否生成新的溢出桶,将新键值对保存至此,并增加计算hmap.count++
这里有些比较有意思的细节:
- key的更新-bulkBarrierPreWrite [TODO,具体细节还未知]
- 检查是否需要Grow
Remove
1
|
delete(m, "key") --> runtime.mapdelete(m, "key")
|
?TODO key/value指正和非指针处理方式稍有不同
Iterator
入口函数mapiterinit(t *maptype, h *hmap, it *iter)
- 构造迭代器对象(使用Copy方式构造)
- 选择迭代器基点(这是随机的,随机的种子来之于…)
1
2
3
4
5
6
7
|
// decide where to start
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
|
Dilatation
既然是hashTable,当数据量大的时候,检索会越来越慢,该如何解决这些问题。Go的Map采用了传统的扩容方式,如下:
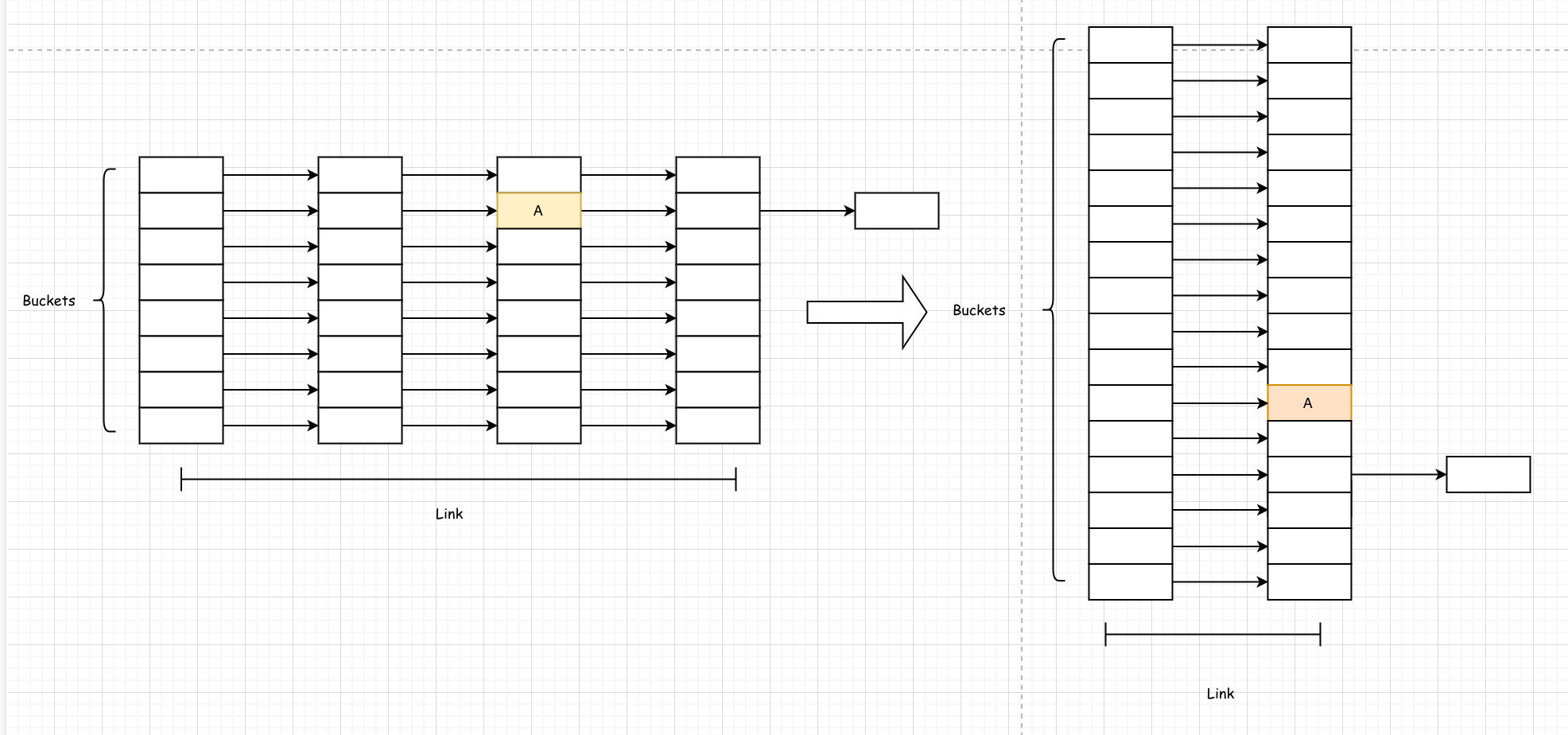
即每次扩容,hashTable Bucket以两倍的方式进行扩容,扩容后,理论上来说,在检索某个值的时候,路径变短了。
这时候同时出现了两个map,旧map的键值对会逐步迁移至新的map,为了性能的考虑,不会一次性迁移,采用*增量扩容*策略,那么就会需要解决如下的问题:
1:达到负载因子(负载因子的单位是cell,即key);2:负载因子为达到,但是溢出的空桶太多(这里的单位是bucket,即溢出的bucket个数),溢出空间使用率就低了
在 Go 的 mapassign 插入 Key 值、mapdelete 删除 key 值的时候都会检查当前是否在扩容中,如果是,则迁移当前key所在的bucket。
除此之外,还有一个比较有意思的问题,键值对达到多少时会触发扩容?在hashTable中有个*loadFactor*的概念,中文意思是*加载因子*或者叫做*负载系数*。
源码中是这么解析的:负载系数太大就会有很多溢出的桶(buckets),如果太小就会浪费太多空间。然后作者就给出了一份测试数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// loadFactor %overflow bytes/entry hitprobe missprobe
// 4.00 2.13 20.77 3.00 4.00
// 4.50 4.05 17.30 3.25 4.50
// 5.00 6.85 14.77 3.50 5.00
// 5.50 10.55 12.94 3.75 5.50
// 6.00 15.27 11.67 4.00 6.00
// 6.50 20.90 10.79 4.25 6.50
// 7.00 27.14 10.15 4.50 7.00
// 7.50 34.03 9.73 4.75 7.50
// 8.00 41.10 9.40 5.00 8.00
//
// %overflow = percentage of buckets which have an overflow bucket
// bytes/entry = overhead bytes used per key/value pair
// hitprobe = # of entries to check when looking up a present key
// missprobe = # of entries to check when looking up an absent key
// |
GoMap使用的是6.5
Grow
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
// 溢出太多空桶而扩容
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// 重置数据
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 将当前溢出桶迁移至`旧`溢出桶
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
|
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 确保迁移了bucket对应的oldbucket
evacuate(t, h, bucket&h.oldbucketmask())
// 再迁移一个标记过的桶
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
// evacDst is an evacuation destination.
type evacDst struct {
b *bmap // current destination bucket
i int // key/val index into b
k unsafe.Pointer // pointer to current key storage
v unsafe.Pointer // pointer to current value storage
}
// 计算真正扩容的旧桶对应的B
func (h *hmap) noldbuckets() uintptr {
oldB := h.B
if !h.sameSizeGrow() {
oldB--
}
return bucketShift(oldB)
}
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 计算出旧桶的位置
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 扩容前桶的个数
newbit := h.noldbuckets()
// 桶还未被迁移
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize))) // 新低位桶
x.k = add(unsafe.Pointer(x.b), dataOffset) // 新低位桶的第一个key
x.v = add(x.k, bucketCnt*uintptr(t.keysize))// 新低位桶的第一个value
// 如果不是等量扩容
if !h.sameSizeGrow() {
// 新高位桶
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))
}
for ; b != nil; b = b.overflow(t) {
// 旧桶key的地址
k := add(unsafe.Pointer(b), dataOffset)
// 旧桶value的地址
v := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
top := b.tophash[i]
if top == empty {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.indirectkey {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
if !h.sameSizeGrow() {
hash := t.key.alg.hash(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey && !t.key.alg.equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY {
throw("bad evacuatedN")
}
// 设置tophash[i]
b.tophash[i] = evacuatedX + useY
// 迁移的目标
dst := &xy[useY]
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.v = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top
if t.indirectkey {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy value
}
if t.indirectvalue {
*(*unsafe.Pointer)(dst.v) = *(*unsafe.Pointer)(v)
} else {
typedmemmove(t.elem, dst.v, v)
}
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.v = add(dst.v, uintptr(t.valuesize))
}
}
// Unlink the overflow buckets & clear key/value to help GC.
if h.flags&oldIterator == 0 && t.bucket.kind&kindNoPointers == 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 数据已全部迁移完毕,清理相关变量值,不会影响到迭代器,即迭代器还是可以方位就的数据
if h.nevacuate == newbit {
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}
|
*注*:
- 如果有迭代器在迭代,那么旧的桶不会被迁移
- sameSizeGrow = 8:当前字典增长到新字典并且保持相同的大小
Refernce
google hashmap load factor
wiki
Other Special Function or Value
hashFunction
TODO
ToHash[0]
桶的迁移进度状态
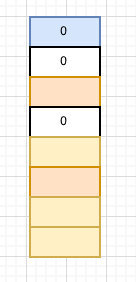
槽为空,即该桶无元素
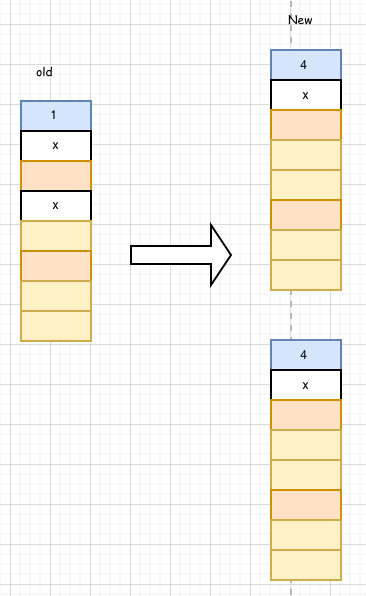
槽为空,并且桶被迁移到新的地方
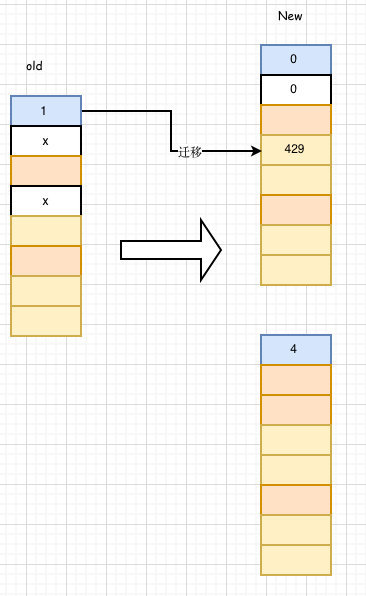
键值对合法,键值对被迁移到新表的前半位置
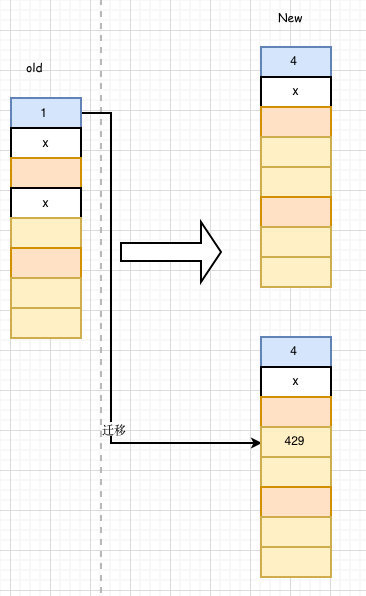
键值对合法,键值对被迁移到新表的**后半位置
bucketShift()
1
2
3
4
5
6
7
8
9
10
|
// bucketShift returns 1<<b, optimized for code generation.
func bucketShift(b uint8) uintptr {
if sys.GoarchAmd64|sys.GoarchAmd64p32|sys.Goarch386 != 0 {
b &= sys.PtrSize*8 - 1 // help x86 archs remove shift overflow checks
// 4 * 8 - 1 = 31
// b &= 31 = b &= 1111 1 即b的取值范围[0, 1111 1],再看下面可知,被限制在 1<<31内
// 在[sys.GoarchAmd64|sys.GoarchAmd64p32|sys.Goarch386],这几种架构中被限制
}
return uintptr(1) << b
}
|
FAQ
什么时候触发增量迁移动作?
insert或者delete操作时触发迁移动作的检查,相关的代码段如下:
1
2
3
|
if h.growing() {
growWork(t, h, bucket)
}
|
Refernce
深入理解 Go map:初始化和访问元素
如何设计并实现一个线程安全的 Map ?(上篇)
how-the-go-runtime-implements-maps-efficiently-without-generics
Author
Rg
LastMod
2019-04-05
License
本文采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可